Los pasados 19 y 20 de Junio estuve de nuevo en la AOS. Esta vez se celebró en Gijón, una ciudad preciosa que no os voy a descubrir ahora.
No elegí el alojamiento oficial de la organización (camping de Deva) por problemas logísticos y me decanté por uno de los hoteles con los la organización nos ofrecía descuentos, el Hotel Asturias. Fue un gran acierto, el Hotel tiene una ubicación magnifica, impresionante, quería decirlo pero no me enrollo mas, vamos a lío.
Que es una AOS (Agile Open Space)
Un open space es un evento auto organizado por los asistentes a la misma. Básicamente: No hay agenda, la agenda se hace al inicio de cada día de AOS. Tampoco hay propuestas previas, las propuestas se presentan al inicio de cada día y se eligen por los asistentes. Si queréis una explicación mas profunda podéis verlo en la pagina de la organización
Si ya lo habéis leído, solo os comento una pequeña reflexión: De una AOS te llevarás lo que quieras llevar, depende de tí y para aprovechar una AOS, hay que ir con las pilas puestas, es un evento muy exigente y hacer de «mariposa» es mas que necesario para poder aguantar el ritmo (buscad «abeja, mariposa y open space»).
Porque mola una AOS
En una AOS lo más habitual es tener debates muy abiertos, con mucha libertad para participar, para aportar y poder recoger otros puntos de vista y experiencias. Aunque puede haber reuniones unidireccionales, la gran mayoría son mesas redondas.
Una de las cosas que más valoro es que recoges muchas experiencias de verdad, no de libro. Casos de uso de agile en entorno reales y duros como la vida misma. En otro tipo de reuniones suele haber mucha teoría y además, todo está muy preparado. El ponente prácticamente está pasando un examen sobre lo que cuenta, no te tienes que preocupar de ser «correcto», solo de aportar y recoger todo lo posible.
Algunas reuniones a las que fui
SAFe
No quiero acercarme a los frameworks y métodos en general para escalar agile que están saliendo en los últimos años. Tengo mis razones para no hacerlo pero no podía dejar pasar la oportunidad de tener un debate al respecto y no me arrepentí. El debate estuvo genial, intenso, con gente que está en el día a día usando SAFe y que nos contó como lo están aplicando. Me lleve una primera impresión de las soluciones que SAFe intenta aplicar a los problemas que encuentras al querer escalar. Fue una de la reuniones más interesantes (para mí, claro).
AARRR + story mapping
Fui a la AOS en tren desde Madrid. Son 5 horas y media pero no me importa porque me encanta el tren. Además me da la oportunidad de ir viendo vídeos (previamente descargados, lo de la wifi es ciencia ficción) que tengo atrasados desde hace tiempo.
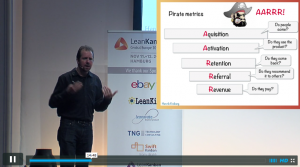
Precisamente uno de los que más me ha gustado últimamente es la keynote de Henrik Kniberg en la pasada ALE , sobre el «entregable» de cada spring, en el que hablaba, entre otras cosas, de las métricas pirata.
Por eso, en cuanto se planteó una charla sobre AARRR e story mapping no me lo pensé ni un momento, estaba muy arriba en mi lista.
La charla no me defraudo, una buena explicación de como complementar un story mapping con técnicas AARRR para darle valor (la medida del valor) a los elementos planificados.
Siempre hablamos de priorizar las historias a planificar en el spring por su valor (de negocio) pero, como se consigue saber esa valoración? Intuición? Inspiración divina? Lo fácil que sea o chulo que parezca? Encuestas a usuario? Esta charla me clarifico formas de encauzar esas decisiones.
#noprojects
#noproject es otra de las corrientes que hay por la comunidad, igual que #noestimates y otras. Que es un proyecto? Desde pequeños nos han enseñado que para hacer un proyecto necesitamos un alcance + un presupuesto (recurso) + un deadline. No sé de qué mágica forma cumplir con scope, budget y fecha asegura reportar un beneficio a nuestro cliente pero en cualquier caso la verdad es que esto cuadra muy mal con el desarrollo de software.
PMI define un proyecto como un esfuerzo encaminado a conseguir un objetivo en una fecha determinada. (Yo no creo que tenga un fin definido y lo del principio, podríamos discutir mucho cuando empieza un proyecto). Es necesario un alcance? No se puede conseguir el objetivo mejor con sucesivas entregas? Tiene fin un proyecto software? Mucho que discutir ahí, desde que un alcance no se conoce (caminante no hay camino…) hasta que el único proyecto sin cambios es un proyecto que no se usa por nadie.
Equipos desorganizados
Otra de las charlas que me impactó fue la relacionada con equipos desorganizados . Realmente debe haber un «equipo»? Es el equipo la forma ideal de trabajar? Es lógico que los proyectos te «toquen»? No es más lógico que tú elijas a que proyectos te apuntas? Y es más, con qué nivel de compromiso te apuntas, no siempre tienes la misma disposición, somos personas con vida en el trabajo y fuera de él, con altibajos no deseados y altibajos deseados. No es más lógico una forma de trabajo estilo freelance?. Mucho en lo que pensar porque la verdad es que la uniformización en la forma de trabajar puede dar una imagen de orden y eficiencia pero no es natural que todos hagamos las cosas de la misma forma todo el tiempo….
Una parte muy positiva que me llevo de la charla es cuestionarlo todo, cuestionar en que nos basamos para pensar que hay que hacer las cosas como las hacemos. La charla fue genial, muy abierta y con muchas opiniones.
Fracaso Agile
En esta reunión me lleve uno de los problemas que cada vez más común, en el afán de ser agiles, estamos adoptando las técnicas pero no los principios y valores.
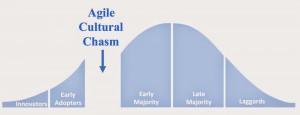
http://cmforagile.blogspot.com.es/2015/04/have-you-crossed-agile-chasm.html
Se está vaciando de contenido. Estamos cayendo por el precipicio? Me recuerda a algo que ocurre mucho con las matemáticas, cuando ante un problema el niño al que estas intentando enseñar a pensar cómo resolver te pregunta «pero, es de sumar o de restar». Aplicando solo el método de resolución no vamos a saber resolver el problema.
Otras que no pude ir
PopcornFlow
Una de las que no pude asistir fue una charla sobre una experiencia usando PopcornFlow. Cosa de la AOS y de no poder estar en varios sitios a la vez. Da la casualidad que en el tren venia viendo un vídeo de Claudio Perrone sobre A3 Thinking y PopcornFlow y llegue a Gijón justo antes de empezar con PopcornFlow, con lo que no sabía de qué iba.

En el viaje de vuelta terminé el vídeo y la verdad es que tiene una pinta fantástica y queda anotado en mi backlog buscar experiencias usándolo.
#NoEstimates
Otra a la que no pude ir… Esta tengo muy clara la «teoría» y estoy totalmente de acuerdo con la filosofía que hay tras ello, pero quiero recoger como se usa en proyectos de verdad… Al backlog…
Equipo AOS
Desde aquí quiero trasmitir mi enorme agradecimiento al equipo organizador de la AOS. Cuando piensas en la cantidad de curro y de ilusión que hay que echar para organizar algo como esto, alucinas. Muchas gracias por vuestro esfuerzo y dedicación, nos hicisteis disfrutar de una AOS genial.

Disclaimer
Este articulo no pretende ser una valoración y ni siquiera una descripción de las charlas que hubo, el contenido fue mucho mas amplio y las discusiones mucho mas ricas de lo que soy capaz de poner y además, sobre la AOS hay tantas conclusiones como personas asistieron, cada cual se he llevado la suya. Solo representa una parte de lo que yo me he llevado.
Ah tambien me he llevado esta foto: