JAXB, acrónimo de ‘Java Architecture for Xml Binding‘, es un API para convertir objetos Java en xml y leer esos mismos xml para obtener objetos Java, que desde la versión 7 tenemos disponible en nuestros JDKs.
Recientemente nos surgió la necesidad, en uno de los proyectos en los que trabajo, de poder guardar ‘evidencias’ de objetos durante la ejecución de una serie de programas a modo de registro para poder analizar el comportamiento y evolución de una serie de datos calculados.
La primera idea para hacer esto sería el escribir un método ‘toString’ que nos devuelva los valores del objeto de tal forma que los podamos ir volcando a uno o varios ficheros, para luego poder analizarlos.
Pero fue esa misma necesidad de poder analizarlos posteriormente la que me hizo pensar en hacer algo más elaborado, de forma que no solo pudiésemos obtener una representación de cada objeto en un momento dado, si no también poder luego explotar esa información desde nuestro aplicación de análisis.
Así fue como decidí tirar de JAXB, ahora que se ha incorporado a Java 7, pensando en obtener una representación que no dependiese de formatos propios y fuese fácilmente explotable.
La ventaja de JAXB reside en su capacidad de realizar ‘marshal’ y ‘unmarshal’ de objetos Java de forma directa, mediante el uso de anotaciones para indicar qué campos son los que queremos incluir en el xml, de una forma rápida, sencilla y no dependiente de un esquema.
El no depender de un esquema nos aporta además la ventaja añadida de poder realizar cambios sobre los objetos sin necesitar de realizar cambios en el parser que usáramos para convertir a xml y viceversa.
Para ver lo sencillo que es, planteemos un ejemplo.
Supongamos que tenemos una Clase Empresa:
package com.art4software.java.jaxb.example.po;
import java.util.ArrayList;
import javax.xml.bind.annotation.XmlElement;
import javax.xml.bind.annotation.XmlRootElement;
import javax.xml.bind.annotation.XmlType;
import com.art4software.java.jaxb.example.MarshalClass;
@XmlRootElement
@XmlType (propOrder = { "nombreEmpresa", "idEmpresa", "direccion", "numEmpleados", "empleados" })
public class Empresa extends MarshalClass {
private int idEmpresa;
private String nombreEmpresa;
private String direccion;
private int numEmpleados;
private ArrayList<Empleado> empleados;
public int getIdEmpresa() {
return idEmpresa;
}
@XmlElement
public void setIdEmpresa(int idEmpresa) {
this.idEmpresa = idEmpresa;
}
public String getNombreEmpresa() {
return nombreEmpresa;
}
@XmlElement
public void setNombreEmpresa(String nombreEmpresa) {
this.nombreEmpresa = nombreEmpresa;
}
public String getDireccion() {
return direccion;
}
@XmlElement
public void setDireccion(String direccion) {
this.direccion = direccion;
}
public int getNumEmpleados() {
return numEmpleados;
}
@XmlElement
public void setNumEmpleados(int numEmpleados) {
this.numEmpleados = numEmpleados;
}
public ArrayList<Empleado> getEmpleados() {
return empleados;
}
@XmlElement
public void setEmpleados(ArrayList<Empleado> empleados) {
this.empleados = empleados;
}
}
Como podemos ver nuestra Empresa tiene Empleados:
package com.art4software.java.jaxb.example.po;
import java.util.Date;
import javax.xml.bind.annotation.XmlElement;
import javax.xml.bind.annotation.XmlRootElement;
import com.art4software.java.jaxb.example.MarshalClass;
@XmlRootElement(name="Empl")
public class Empleado extends MarshalClass{
private int id;
private String nombre;
private String titulo;
private boolean activo=false;
private Integer numeroEmpl;
private Date fechaAlta;
public int getId() {
return id;
}
@XmlElement
public void setId(int id) {
this.id = id;
}
public String getNombre() {
return nombre;
}
@XmlElement
public void setNombre(String nombre) {
this.nombre = nombre;
}
public String getTitulo() {
return titulo;
}
@XmlElement
public void setTitulo(String titulo) {
this.titulo = titulo;
}
public boolean isActivo() {
return activo;
}
@XmlElement
public void setActivo(boolean activo) {
this.activo = activo;
}
public Integer getNumeroEmpl() {
return numeroEmpl;
}
@XmlElement
public void setNumeroEmpl(Integer numeroEmpl) {
this.numeroEmpl = numeroEmpl;
}
public Date getFechaAlta() {
return fechaAlta;
}
@XmlElement
public void setFechaAlta(Date fechaAlta) {
this.fechaAlta = fechaAlta;
}
}
Si os fijáis usamos 3 anotaciones: XmlRootElement, XmlType y XmlElement.
La primera marca el elemento raíz de nuestra clase (en nuestro caso el nombre de la clase). Con XmlType y la propiedad ‘propOrder’ cambiamos el orden en que se escribirán los atributos en el xml resultante.
Finalmente usando XmlElement en el setter de los atributos que nos interesa que se incluyan en el xml, marcamos los campos de nuestro interés.
Si os fijáis, ambas clases heredan de una tercera clase: MarshalClass.
¿Y para qué?
En mi caso, dado que la acción de guardar ‘evidencias’ se realizará sobre clases distintas, con esta herencia puedo limitar a un tipo común el manejo de las clases a guardar, haciendo que hereden de dicha clase el método de guardado:
package com.art4software.java.jaxb.example;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import javax.xml.bind.JAXBContext;
import javax.xml.bind.JAXBException;
import javax.xml.bind.Marshaller;
public class MarshalClass {
public void generateXML (String nameFile) {
try {
File file = new File (nameFile);
JAXBContext jc = JAXBContext.newInstance(this.getClass());
Marshaller jaxbMarshaller = jc.createMarshaller();
jaxbMarshaller.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, true);
jaxbMarshaller.marshal(this, new FileWriter(nameFile, true));
} catch (JAXBException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Si os fijáis en el código del método, que será común para todos, realizar el Marshal es tan sencillo como:
- Obtener un JAXBContext sobre la clase a representar en xml (en nuestro caso).
- A partir de este contexto crear un ‘Marshaller’
- Configurar el formato de salida.
- Invocar al método para escribir la clase a xml.
En mi ejemplo uso un FileWriter en lugar de un File (cuya declaración he dejado en el ejemplo aunque no se usa) porque así podría ir volcando todas las representaciones a un único fichero, donde se iría añadiendo el xml de cada clase en cada invocación.
Si usáramos el File, estaríamos machacando el contenido si usamos el mismo nombre de fichero, o generando un nuevo fichero por cada invocación usando nombres distintos.
Ahora, para ejecutarlo:
package com.art4software.java.jaxb.example;
import java.util.ArrayList;
import java.util.Date;
import com.art4software.java.jaxb.example.po.Empresa;
import com.art4software.java.jaxb.example.po.Empleado;
/**
*
* @author mvcarrillo
*
*/
public class JAXBExample {
/**
* @param args
*/
public static void main(String[] args) {
marshallingExample();
}
/**
* Crea una empresa y 10.000 empleados.
*/
private static void marshallingExample () {
long time = System.currentTimeMillis();
System.out.println ("Inicio: " + new Date(time));
Empresa cc = new Empresa ();
cc.setIdEmpresa(1);
cc.setDireccion("En la nube");
cc.setNombreEmpresa("Art4Software");
cc.setNumEmpleados(25000);
ArrayList<Empleado> alCU = new ArrayList<Empleado> ();
int init = 20000;
for (int i=1;i<10000;i++) {
Empleado cu = new Empleado ();
cu.setId(i);
cu.setActivo(true);
cu.setNumeroEmpl(new Integer (init++));
cu.setNombre("Empleado " + i);
cu.setTitulo("SW Architect");
cu.setFechaAlta(new Date(System.currentTimeMillis()));
alCU.add(cu);
}
cc.setEmpleados(alCU);
long time2 = System.currentTimeMillis();
System.out.println ("Generacion: " + (time2-time) + " milisegundoss - Marshaling: " + new Date (time2));
cc.generateXML("Art4Software-Datos.xml");
long time3 = System.currentTimeMillis();
System.out.println ("Fin: " + new Date(System.currentTimeMillis()) + " - Tiempo Total: " + (time3 - time) + " milisegundos");
}
}
Para realizar la conversión de todos los objetos, tan solo necesitamos invocar al método sobre el objeto ‘Empresa’, sin tener que hacerlo por cada objeto del tipo ‘Empleado’ que pueda contener en el ArrayList.
Como podéis ver, hemos metido unas trazas para ver cuánto tiempo tarda en realizar la creación de los objetos y el volcado a xml, obteniendo los siguientes tiempos (con JDK 1.7u21, eclipse Indigo, en un PhenomII x6 1090T con 8GB RAM):
Inicio: Fri Jun 07 22:38:56 CEST 2013
Generacion: 29 milisegundoss – Marshaling: Fri Jun 07 22:38:56 CEST 2013
Fin: Fri Jun 07 22:38:57 CEST 2013 – Tiempo Total: 312 milisegundos
Menos de medio segundo es un tiempo realmente bueno para lo que necesitamos realizar.
Ahora, a partir de aquí podríamos crearnos una aplicación que cargase un xml, o los xml contenidos en un directorio para una fecha concreta, y obtuviese todos los objetos grabados de nuevo para analizar los resultados.
Por último, importante tener en cuenta la siguiente tabla con la equivalencia de tipos de datos:
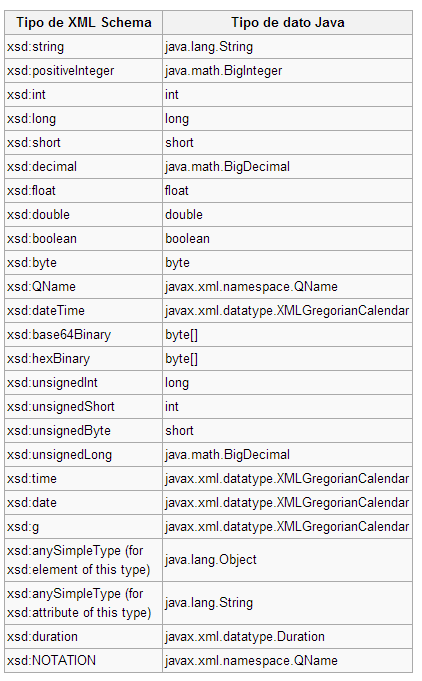
Correspondencia de datos por defecto.